ELKF日志学习(四)FileBeat基础配置
前言
在 《ELKF日志学习(一)前言》 中介绍过 FileBeat,是一个轻量级的开源日志文件数据搜集器,负责对服务的日志进行收集。
因为
logstash是jvm跑的,资源消耗比较大,所以后来作者又用golang写了一个功能较少但是资源消耗也小的轻量级的logstash-forwarder。
不过作者只是一个人,加入http://elastic.co公司以后,因为es公司本身还收购了另一个开源项目packetbeat,而这个项目专门就是用golang的,有整个团队,所以es公司干脆把logstash-forwarder的开发工作也合并到同一个golang团队来搞,于是新的项目就叫FileBeat了。
摘自:《一篇文章搞懂filebeat(ELK)》 - HZhuizai
代码仓库
实际应用
个人觉得,学习是为了更好的运用,所以直接在这里写上 FileBeat 在实际中的应用。
举个例子:
我们有 web、api、cron 三个系统,我们需要收集这几个系统的日志。
只需要在每个服务中安装启动 FileBeat,配置好监听的文件,一旦文件发生变化,写入指定的位置。
如果是 Docker 服务,只需要共享服务的日志文件,将 FileBeat 单独放在一个容器中运行即可(每个单独的服务配置一个)。
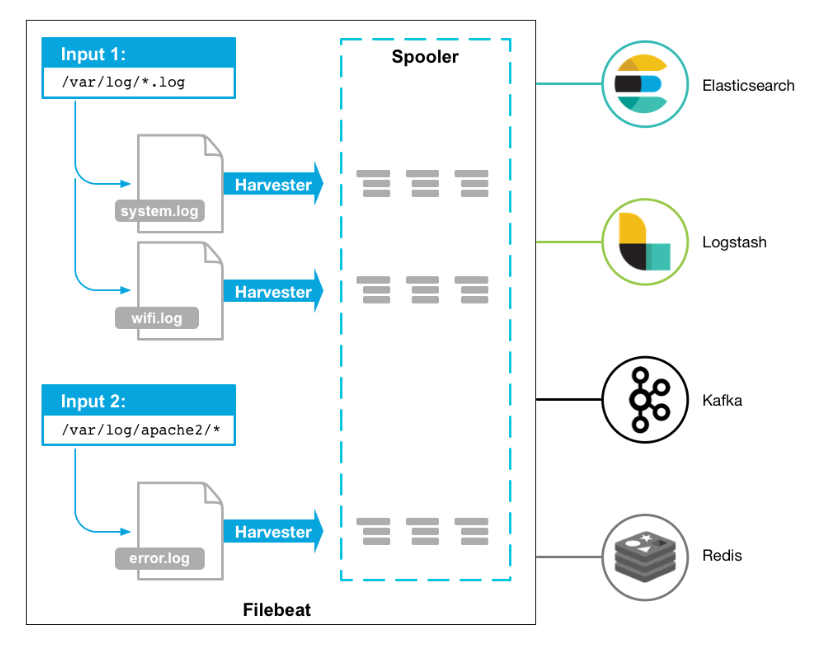
工作原理
Filebeat 根据用户指定的配置 input,读取文件,一个文件一个 harvester。
其中,input 是管理 harvester 的;harvester 的作用是逐行读取文件,并把内容发送到输出。
Filebeat 会记住每个文件的状态,及 harvester 读取的最后一个偏移量(即位置)。
输出 可以是 Elasticsearch、Kafka、Logstash、redis 等。
配置解析
输入配置
这里指定输入类型为 log,且路径是 /var/log/nginx/access.log
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log为了能够方便后续的识别,这里添加一个来源。
这里的 fields 是自定义的,你可以按照自己团队的规范定义。
filebeat.inputs:
- type: log
enabled: true
fields:
source: nginx_access_log
paths:
- /var/log/nginx/access.log输出配置
上述已经说明了,我们可以输出的类型有很多,这里配置一下 Logstash。
output.logstash:
hosts: ['logstash:5044']扩展一下,如果有多个 Logstash 服务,该如何配置?
答:使用 loadbalance: true。
output.logstash:
hosts: ['logstash:5044', 'logstash1:5044']
loadbalance: true最后
到此为止,FileBeat 的基础配置是介绍结束了。
它难道就这一点功能么?
NO!!!
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!