Docker ELKF平台搭建 单机
申明
本文是基于 hub.docker.com 站点提供的 Docker 容器进行搭建的,且是 单机 ,仅用于学习。
简介
ELKF 是 Elasticsearch 、 Logstash 、 Kibana 、 Filebeat。
filebeat 是轻量级的开源日志文件数据搜集器,负责对服务的日志进行收集。
logstash 是数据收集引擎,可以对数据进行过滤、分析、丰富、统一格式等操作,存储到用户指定的位置,包含但不限于文件、 elasticsearch 。
elasticsearch 是存储、搜索和分析引擎,特点是高可伸缩、高可靠和易管理等。
kibana 是数据分析和可视化平台,通常依赖 elasticsearch 。
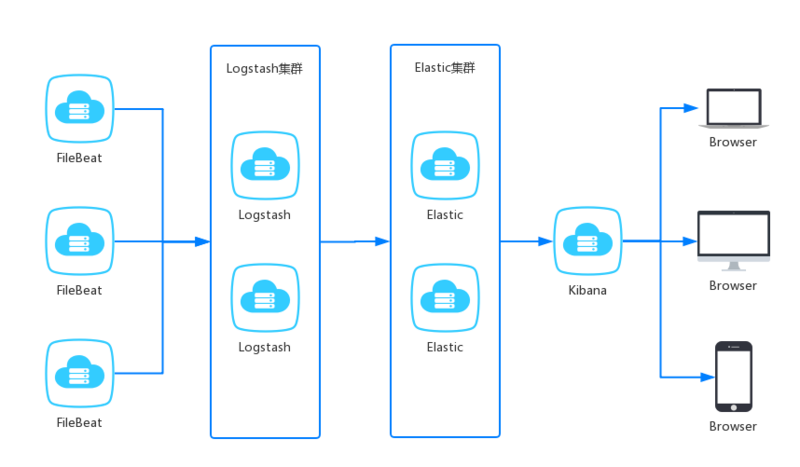
图片来源于网络
说明
为了能够达到更好的学习效果,这里将 elasticsearch 设置成了无需密码的状态。
同时,elasticsearch 也用的是免费版。
仓库
镜像版本
Docker 镜像版本: 7.1.1。
logstash:7.1.1kibana:7.1.1elasticsearch:7.1.1store/elastic/filebeat:7.1.1
配置文件目录
elkf
├─elasticsearch
│ └─elasticsearch.yml
├─filebeat
│ └─filebeat.yml
├─kibana
│ └─kibana.yml
└─logstash
├─logstash.yml
└─pipeline
└─logstash.conf编写 docker-compose.yml
version: "3"
services:
filebeat:
image: store/elastic/filebeat:7.1.1
volumes:
- ./logs:/var/log
- ./elkf/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
user: "root"
elasticsearch:
image: elasticsearch:7.1.1
ports:
- "9200:9200"
- "9300:9300"
volumes:
- ./elkf/elasticsearch/data:/usr/share/elasticsearch/data
- ./elkf/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml:ro
environment:
ELASTICSEARCH_USERNAME: "root"
ELASTICSEARCH_PASSWORD: "123456"
ES_JAVA_OPTS: "-Xmx256m -Xms256m"
discovery.type: single-node
xpack.security.enabled: 'false'
logstash:
image: logstash:7.1.1
ports:
- "5044:5044"
volumes:
- ./elkf/logstash/pipeline:/usr/share/logstash/pipeline:ro
- ./elkf/logstash/logstash.yml:/usr/share/logstash/config/logstash.yml:ro
environment:
LS_JAVA_OPTS: "-Xmx256m -Xms256m"
depends_on:
- elasticsearch
kibana:
image: kibana:7.1.1
ports:
- "5601:5601"
volumes:
- ./elkf/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml:ro
environment:
I18N_LOCALE: zh-CN
depends_on:
- elasticsearchfilebeat部分
filebeat:
image: store/elastic/filebeat:7.1.1
volumes:
- ./logs:/var/log
- ./elkf/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
user: "root"./logs:/var/log 是将本地的 log 映射到容器中。我这里是将日志存储在容器外的
./elkf/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro 是将容器外的配置映射到容器内。
filebeat.yml 文件:
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
filebeat.inputs:
- type: log
enabled: true
fields:
log_source: nginx_access_log
paths:
- /var/log/nginx/access.log
- type: log
enabled: true
fields:
log_source: nginx_error_log
paths:
- /var/log/nginx/error.log
output.logstash:
hosts: ['logstash:5044']elasticsearch部分
elasticsearch:
image: elasticsearch:7.1.1
ports:
- "9200:9200"
- "9300:9300"
volumes:
- ./elkf/elasticsearch/data:/usr/share/elasticsearch/data
- ./elkf/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml:ro
environment:
ELASTICSEARCH_USERNAME: "root"
ELASTICSEARCH_PASSWORD: "123456"
ES_JAVA_OPTS: "-Xmx256m -Xms256m"
discovery.type: single-node
xpack.security.enabled: 'false'ports 用于端口映射。
./elkf/elasticsearch/data:/usr/share/elasticsearch/data 将 elasticsearch 的数据存储到容器外,防止容器重新创建,造成数据丢失。
environment 设置一些容器所需要的一些环境变量。
xpack.security.enabled: 'false' 这个是设置使用 elasticsearch 的 基本许可证。因为默认的有使用时间限制。
elasticsearch.yml 文件:
## Default Elasticsearch configuration from Elasticsearch base image.
## https://github.com/elastic/elasticsearch/blob/master/distribution/docker/src/docker/config/elasticsearch.yml
#
cluster.name: "docker-cluster"
network.host: 0.0.0.0
## X-Pack settings
## see https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-xpack.html
#
# xpack.license.self_generated.type: triallogstash部分
logstash:
image: logstash:7.1.1
ports:
- "5044:5044"
volumes:
- ./elkf/logstash/pipeline:/usr/share/logstash/pipeline:ro
- ./elkf/logstash/logstash.yml:/usr/share/logstash/config/logstash.yml:ro
environment:
LS_JAVA_OPTS: "-Xmx256m -Xms256m"
depends_on:
- elasticsearchdepends_on 是因为 logstash 将解析之后的数据存储到 elasticsearch 中,所以 logstash 依赖 elasticsearch 。
logstash.yml 文件:
## Default Logstash configuration from Logstash base image.
## https://github.com/elastic/logstash/blob/master/docker/data/logstash/config/logstash-full.yml
#
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ]
## X-Pack security credentials
#
xpack.monitoring.enabled: true
path.logs: /var/log/logstash
pipeline.workers: 4logstash.conf 文件:
input {
beats {
port => 5044
}
}
## Add your filters / logstash plugins configuration here
filter {
if [fields][log_source] == "nginx_access_log" {
grok {
match => {
"message" => '%{IPV4:remote_addr} - %{USERNAME:remote_user} \[%{HTTPDATE:timestamp}\] \"%{WORD:request_method} %{URIPATHPARAM:request_uri} HTTP/%{BASE10NUM:http_version}\" %{IPORHOST:http_host} %{INT:status} %{INT:request_length} %{INT:body_bytes_sent} %{QS:http_referer} %{QS:http_user_agent} %{BASE10NUM:request_time} (?<upstream_response_time>([0-9]+.[0-9]+)|-)'
}
remove_field => "message"
}
mutate {
convert => ["upstream_response_time", "float"]
convert => ["request_time", "float"]
convert => ["http_version", "float"]
convert => ["status", "integer"]
}
}
if [fields][log_source] == "nginx_error_log" {
grok {
match => [
"message", '%{TIMESTAMP_ISO8601:timestamp} \[%{DATA:log_level}\] %{NUMBER:pid:int}#%{NUMBER}: %{DATA:error_message}, client: %{IP:client_ip}, server: %{HOSTNAME:request_server}, request: \"%{WORD:request_method} %{URIPATHPARAM:request_uri} HTTP/%{BASE10NUM:http_version}\", upstream: \"%{URI:upstream}\", host: \"%{HOSTNAME:request_host}\", referrer: \"%{URI:request_referrer}\"',
"message", '(?<timestamp>%{YEAR}/%{MONTHNUM}/%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?%{ISO8601_TIMEZONE}?) \[%{DATA:log_level}\] %{NUMBER:pid:int}#%{NUMBER}: %{DATA:error_message}, client: %{IP:client_ip}, server: %{HOSTNAME:request_server}, request: \"%{WORD:request_method} %{URIPATHPARAM:request_uri} HTTP/%{BASE10NUM:http_version}\", upstream: \"%{URI:upstream}\", host: \"%{HOSTNAME:request_host}\", referrer: \"%{URI:request_referrer}\"',
"message", "%{TIMESTAMP_ISO8601:timestamp} \[%{LOGLEVEL:log_level}\]\s{1,}%{GREEDYDATA:error_message}"
]
remove_field => "message"
}
}
}
output {
elasticsearch {
index => "%{[fields][log_source]}-%{+YYYY.MM.dd}"
hosts => "elasticsearch:9200"
}
}kibana部分
kibana:
image: kibana:7.1.1
ports:
- "5601:5601"
volumes:
- ./elkf/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml:ro
environment:
I18N_LOCALE: zh-CN
depends_on:
- elasticsearch同样, kafka 依赖 elasticsearch 。
kabana.yml 文件:
## Default Kibana configuration from Kibana base image.
## https://github.com/elastic/kibana/blob/master/src/dev/build/tasks/os_packages/docker_generator/templates/kibana_yml.template.js
#
server.name: kibana
server.host: 0.0.0.0
elasticsearch.hosts: [ "http://elasticsearch:9200" ]可能需要扩展的部分
logstash将行日志转换成json
通过 grok 来解析
grok正则的编写验证
官方有一部分预定义 grok 的表达式,可以参考,我们也可以编写一些预定义的表达式供后续使用。
Grok Debugger 可以帮助我们验证调试解日志的正则。(可能需要自备梯子)
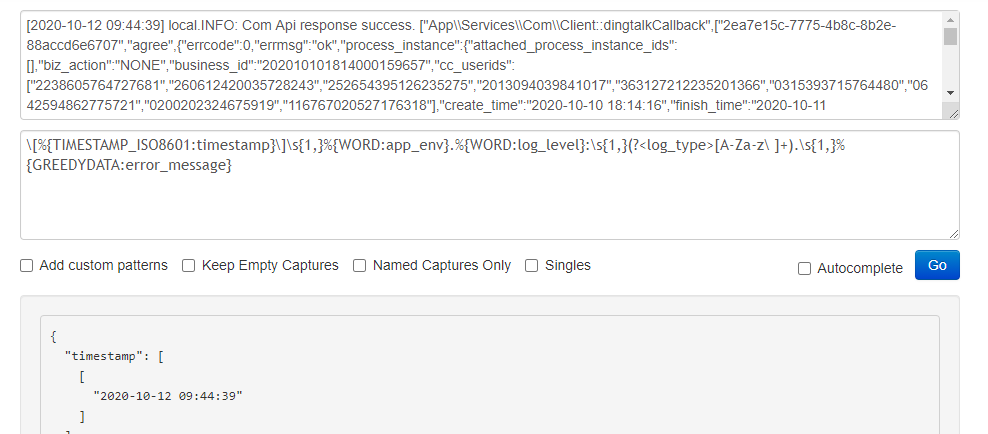
Kibana 也提供了相应的工具,只不过没那么好用罢了。
filebeat多行解析
直接上 Demo :
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
filebeat.inputs:
- type: log
enabled: true
fields:
log_source: lumen_log
paths:
- /var/log/lumen/lumen.log
multiline.pattern: '^\[[0-9]{4}-[0-9]{2}-[0-9]{2}'
multiline.negate: true
multiline.match: after
output.logstash:
hosts: ['logstash:5044']这个的意思是根据 multiline.pattern 匹配到的为日志的开头, multiline.match 追加的位置, multiline.negate 是是否为否定模式。
| multiline.negate | multiline.match | 描述 |
|---|---|---|
| true | after | 不符合 multiline.pattern 的,追加 上一个匹配 的一行后面 |
| false | after | 符合 multiline.pattern 的,追加到 上一个不匹配的一行后面 |
| true | before | 不符合 multiline.pattern 的,追加 下一个匹配 的一行前面 |
| false | before | 符合 multiline.pattern 的,追加到 上一个不匹配的一行前面 |
为了方便理解,我们使用的是 true、 after 模式,大致意思是, multiline.pattern 匹配的一行开始,只要不匹配的,都追加到匹配的那一行,直至找到下一个匹配的一行结束。
filebeat不读取某些行
有时候,我们日志中会有一些框架层面的日志,这个我们是不需要看到的,可以通过某些关键字来排除(有利有弊)
Demo 如下:
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
filebeat.inputs:
- type: log
enabled: true
fields:
log_source: lumen_log
paths:
- /var/log/lumen/lumen.log
exclude_lines: ["不需要的关键字1", "不需要的关键字2"]
multiline.pattern: '^\[[0-9]{4}-[0-9]{2}-[0-9]{2}'
multiline.negate: true
multiline.match: after
output.logstash:
hosts: ['logstash:5044']使用
创建索引
1、设置 -> 索引模式 -> 创建索引模式。
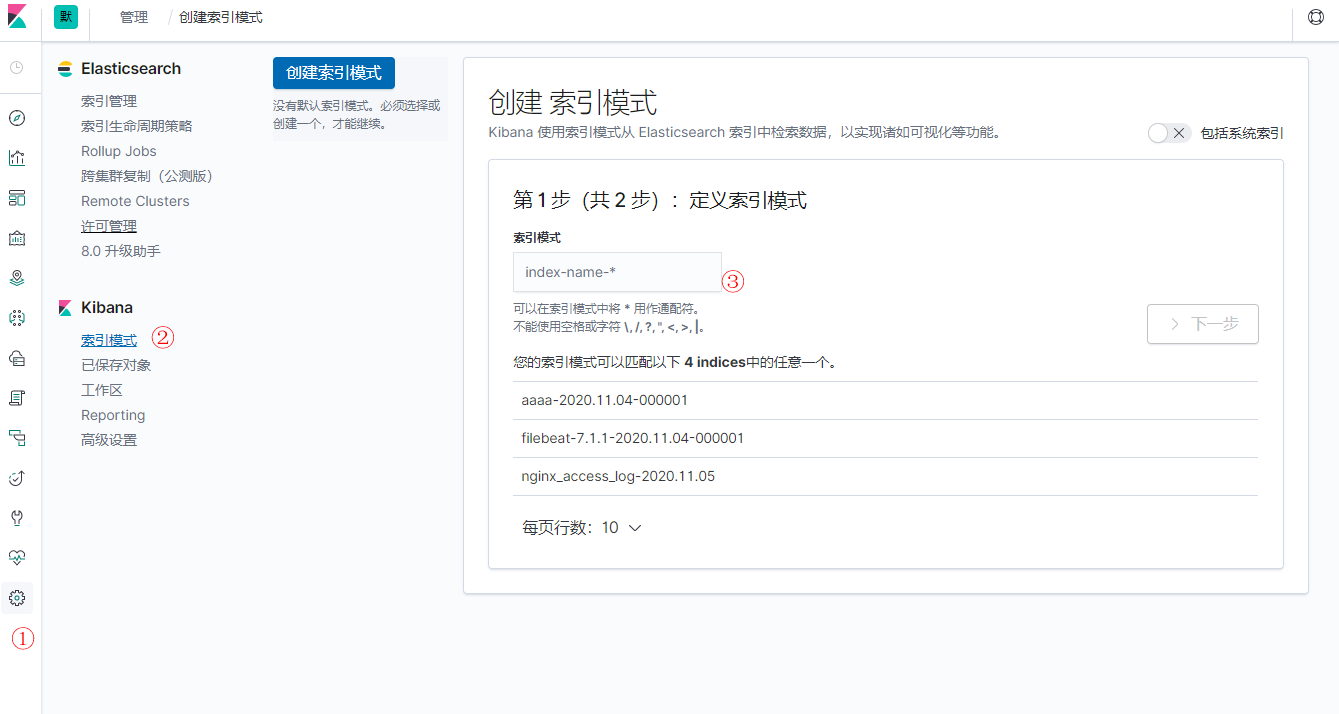
2、检索索引
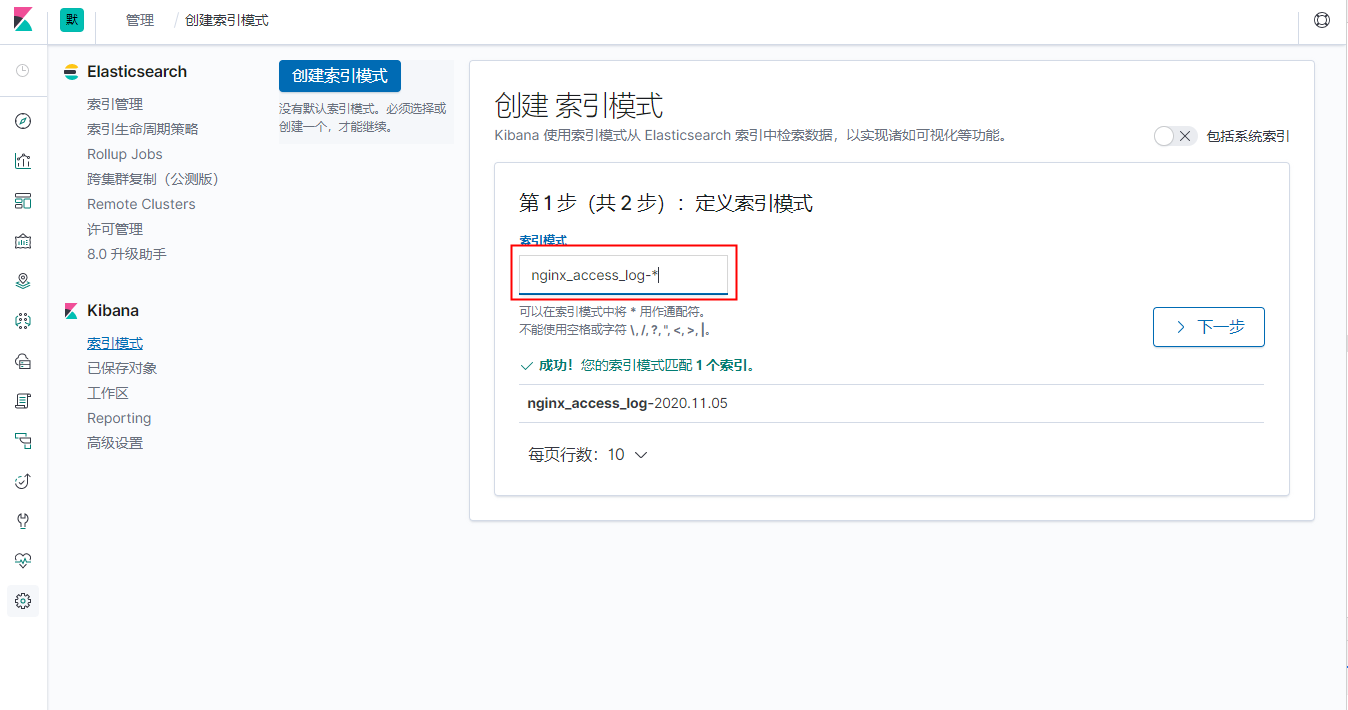
3、配置、创建
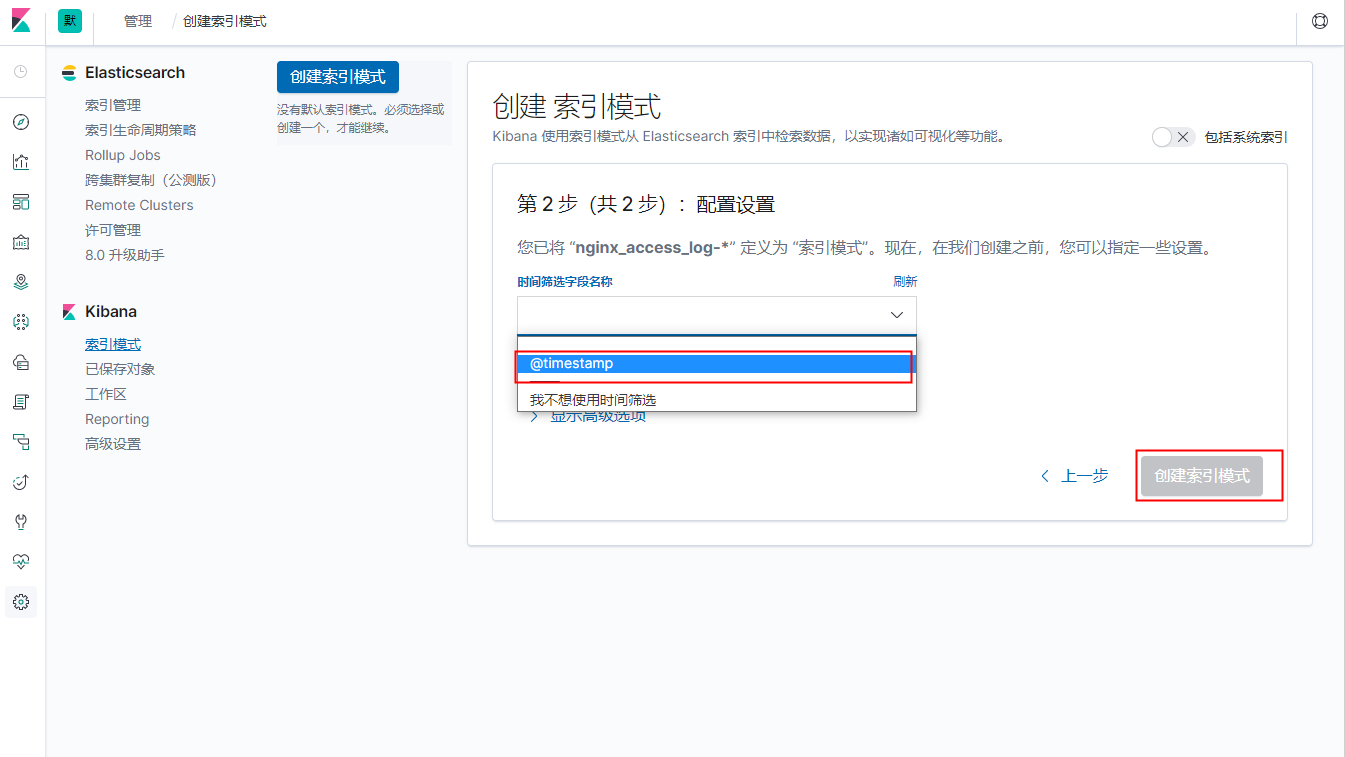
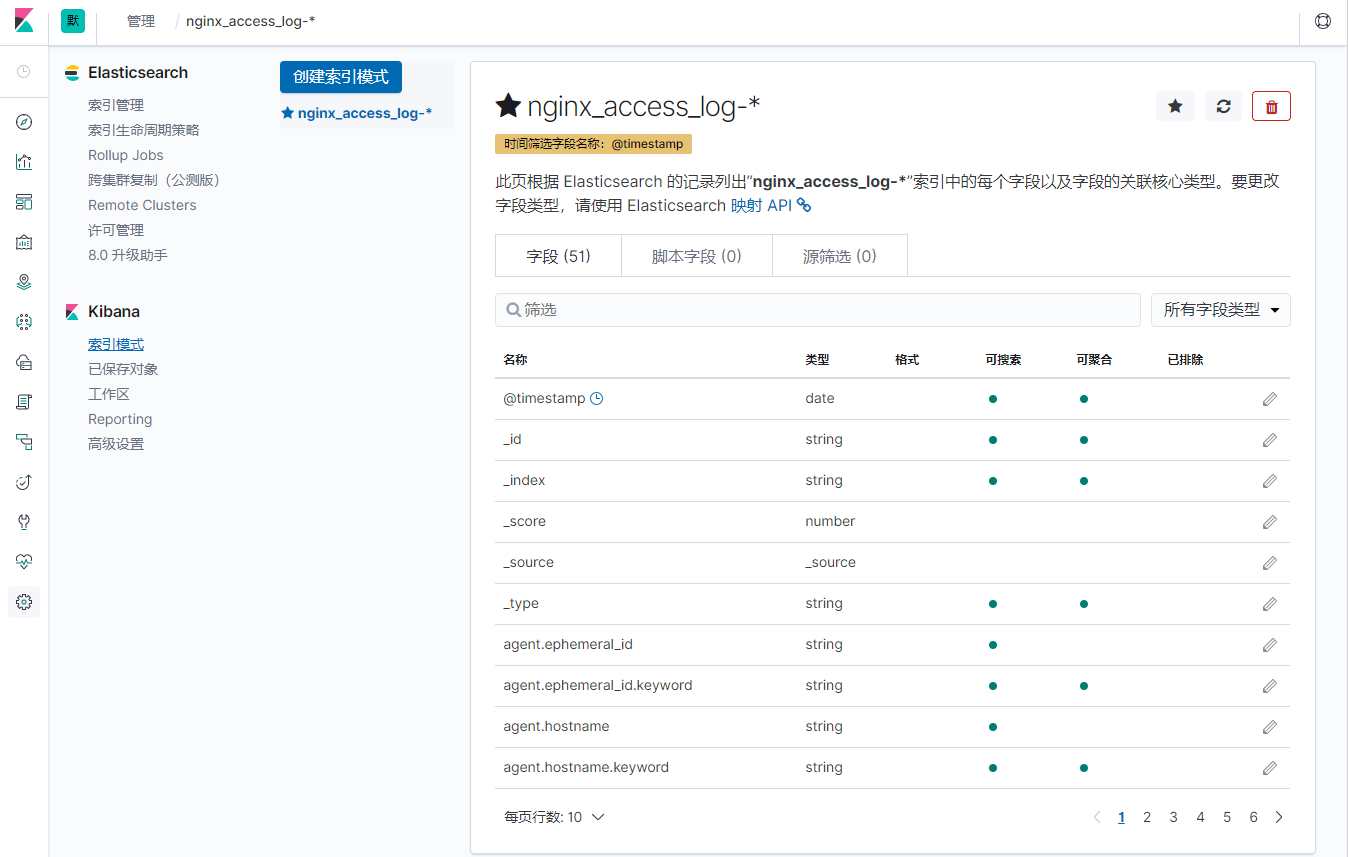
4、创建成功,尽情使用吧
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!